


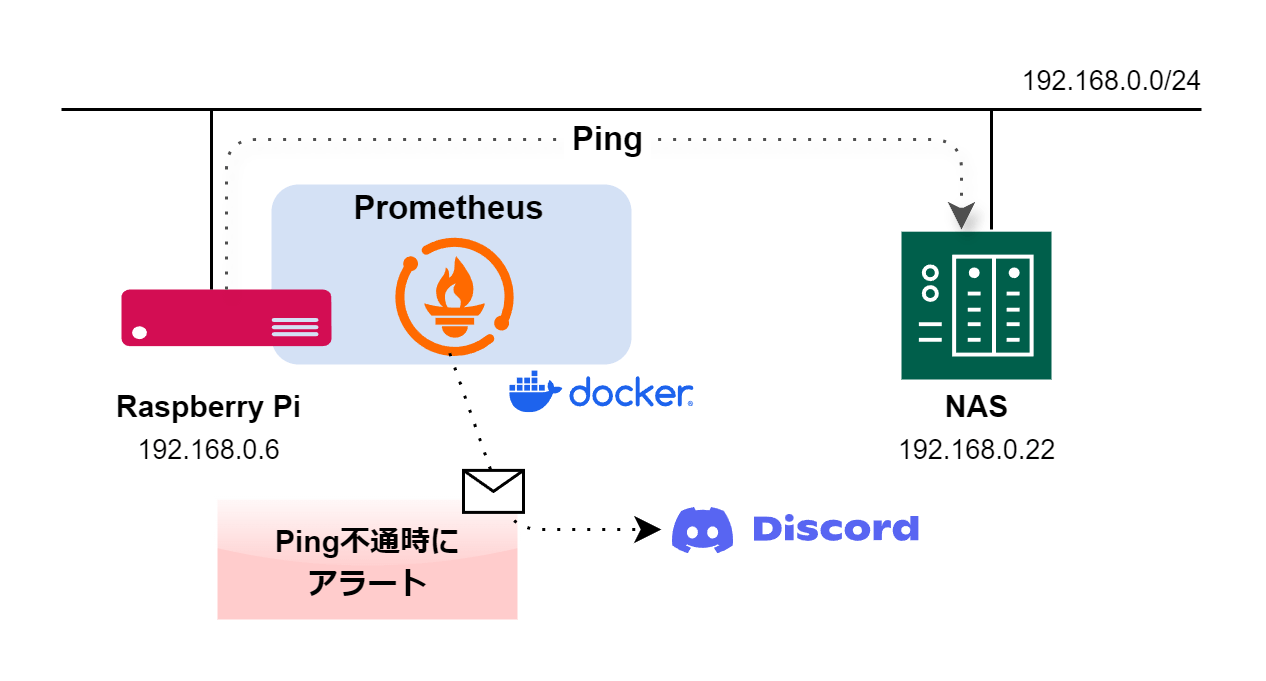
自宅のNASの電気代節約のため、深夜帯に自動電源オフ→明け方に自動電源オンにしている。しかし、稀に自動起動に失敗してしまい、外部から一切のアクセスを受け付けなくなることがある。
NASのネットワークが切れてしまうと、NAS自体のアラートを外部に一切出せなくなるので、不具合に気づくのも遅くなりがちだ。
こうした機器の異変にいち早く気づきたいと思い、端末へのPINGが届かなくなったらDiscordやSlackで通知してくれる仕組みを探してみるとPrometheus(プロメテウス)というオープンソースの監視システムを使うことで実現できると知った。
今回、自宅のLANに接続されているRaspberry PiのDockerコンテナでPrometheusを稼働させ、NASの監視をすることにした。実際に構築してみてZabbixといった他の監視ソリューションに比べて難易度がかなり低いと感じたので、参考にしてみて欲しい。
今回はRaspberry PiでPrometheusを用いた監視システムを構築したが、Dockerが使えるシステムであればOSは問わない。
▼ 低消費電力で安定して稼働し、置きどころにも困らないRaspberry Piはお手軽監視システムにもってこいの存在だ

 Amazon
Amazon Rakuten
RakutenPrometheusはExporter(エクスポーター)という監視対象からデータを取得し、Prometheusが読み取れる形式で受け渡す監視エージェントと組み合わせて使用する。
主なExporterの種類は以下のとおり。
- システム系:Node Exporter(CPU、メモリ、ディスクなどの情報)
- ネットワーク系:Blackbox Exporter(HTTP、PING監視)、SNMP Exporter(ネットワーク機器監視)
- データベース系:MySQL Exporter、PostgreSQL Exporter(DBのメトリクス取得)
- クラウド・コンテナ系:cAdvisor(Dockerコンテナ監視)、Kube-State-Metrics(Kubernetesリソース監視)
PrometheusはPING監視だけでなく、端末のCPU使用率や稼働中のプロセス、その他もろもろまで収集し、監視できてしまう非常に高機能なシステムだが、今のワタシにとってはPING監視のみで十分なので、Blackbox Exporterを用いた最小構成で紹介する。
Docker Composeを使って一度に複数のコンテナを操作したいので、まずは以下のディレクトリ構成でファイルを作成する。yamlファイルの中身は空でよい。
Prometheus_Alertmanager
├── alertmanager
│ └── config.yaml
├── blackbox_exporter
│ └── config.yaml
├── docker-compose.yaml
└── prometheus
├── alert.rules
└── prometheus.yamlここで初めて現れたAlertmanager(アラートマネージャー)は、Prometheusのアラート通知を管理するツールで、Prometheusのアラートを整理し、適切な通知先に送る配達係のような存在である。
核となるdocker-compose.yamlを編集する。
システム本体のPrometheusのほか、Alertmanager、Blackbox Exporterの3つのコンテナで構成している。
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus:/etc/prometheus
command: "--config.file=/etc/prometheus/prometheus.yaml"
ports:
- 9090:9090
extra_hosts:
- "host.docker.internal:host-gateway"
restart: always
alertmanager:
image: prom/alertmanager
container_name: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager
command: "--config.file=/etc/alertmanager/config.yaml"
ports:
- 9093:9093
restart: always
blackbox_exporter:
image: prom/blackbox-exporter:latest
container_name: blackbox_exporter
volumes:
- ./blackbox_exporter/config.yaml:/etc/blackbox_exporter/config.yaml
ports:
- 9115:9115
restart: alwaysつづいて、Prometheusディレクトリの中のファイル2つ。まずはprometheus.yamlを以下のように記述
global:
scrape_interval: 15s # 監視対象をスクレイプ(情報取得)する間隔
evaluation_interval: 15s # アラートルールを評価する間隔
rule_files:
- /etc/prometheus/alert.rules
alerting:
alertmanagers:
- static_configs:
- targets:
- host.docker.internal:9093
scrape_configs:
- job_name: 'NAS_ping'
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets:
- 192.168.0.22 # ここに監視対象端末のIPアドレスを入れる
scrape_timeout: 5s # スクレイプのタイムアウト
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: host.docker.internal:9115同じPrometheusディレクトリのalert.rulesは次のように記述
groups:
- name: NAS_node_alerts
rules:
- alert: NASNodeDown
expr: probe_success{job="NAS_ping"} == 0
for: 30s # 30秒以上DOWNならアラート
labels:
severity: critical
annotations:
summary: "NAS {{ $labels.instance }} is down"
description: "NAS {{ $labels.instance }} のPING応答がありませんでした"alertmanagerのディレクトリに移動し、config.yamlを記述する
route:
receiver: default-receiver
group_by: ['alertname' , 'job']
group_wait: 30s # 最初のアラートは30秒待機後に送信
group_interval: 5m # 新しいアラートが同じグループに追加されても5分に1回送信
repeat_interval: 1d # 同じアラートが継続している場合は 1日に1回再通知
routes:
- receiver: discord
match:
severity: critical # alert.rulesでcriticalに指定されているアラートをdiscordに送る
receivers:
- name: default-receiver
- name: discord
discord_configs:
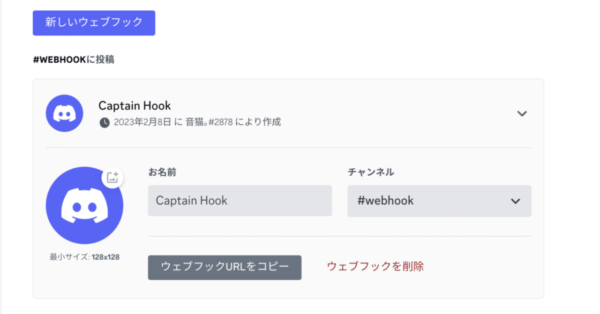
- webhook_url: https://discord.com/api/webhooks/****** # DiscordのWebhook URLを入力DiscordのWebhook URLの取得方法は次のサイトがわかりやすい。
最後のblackbox_exporterのディレクトリに移動し、config.yamlを編集する。ここではHTTP / TCP / ICMP(PING) を用いたモジュールを定義する。
例えばtcp_connectは指定のTCPポートが空いているかどうかの確認しかできないので、SSHサービスが正常に応答しているかを確認したいなら ssh_banner を使うのが良い。ちなみにUDPは確認できない。
modules:
http_2xx:
prober: http
http:
http_post_2xx:
prober: http
http:
method: POST
tcp_connect:
prober: tcp
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: "^+OK"
tls: true
tls_config:
insecure_skip_verify: false
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: "^SSH-2.0-"
irc_banner:
prober: tcp
tcp:
query_response:
- send: "NICK prober"
- send: "USER prober prober prober :prober"
- expect: "PING :([^ ]+)"
send: "PONG ${1}"
- expect: "^:[^ ]+ 001"
icmp:
prober: icmp
timeout: 3sこれですべてのファイルの準備が整った。
トップのPrometheus_Alertmanagerディレクトリに移り、Docker composeで3つのコンテナを起動する。
# コンテナをバックグラウンドで起動
sudo docker-compose up -d
Creating prometheus ... done
Creating alertmanager ... done
Creating blackbox_exporter ... done
# コンテナ動作状況の確認
sudo docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 0.0.0.0:9093->9093/tcp,:::9093->9093/tcp
blackbox_exporter /bin/blackbox_exporter --c ... Up 0.0.0.0:9115->9115/tcp,:::9115->9115/tcp
prometheus /bin/prometheus --config.f ... Up 0.0.0.0:9090->9090/tcp,:::9090->9090/tcp起動後、3つともコンテナがUPしていればOK。
yamlファイルの書き方に誤りがあったりするとコンテナ起動に失敗するので、そんなときはログを確認し原因を探る。
# コンテナ動作状況の確認
sudo docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 0.0.0.0:9093->9093/tcp,:::9093->9093/tcp
blackbox_exporter /bin/blackbox_exporter --c ... Up 0.0.0.0:9115->9115/tcp,:::9115->9115/tcp
prometheus /bin/prometheus --config.f ... Restarting
# ↑ prometheusのコンテナ起動に失敗し、再起動ループに陥っている
# Docker composeのログから"ERROR"に該当する行を抽出する
sudo docker-compose logs | grep ERROR
prometheus | time=2025-02-03T15:02:56.091Z level=ERROR source=main.go:593 msg="Error loading config (--config.file=/etc/prometheus/prometheus.yaml)" file=/etc/prometheus/prometheus.yaml err="parsing YAML file /etc/prometheus/prometheus.yaml: yaml: unmarshal errors:\n line 21: cannot unmarshal !!str `192.168...` into struct { Targets []string \"yaml:\\\"targets\\\"\"; Labels model.LabelSet \"yaml:\\\"labels\\\"\" }"
# ↑ prometheus.ymalの21行目でunmarshalエラー発生。インデント誤りなどがないか確認しようPrometheus の動作確認や、簡単なクエリや設定の確認を行うための管理ページ(Web UI)にアクセスする。Web UIのURLはデフォルトで http://<PrometheusサーバーのIPアドレス>:9090 になっている。
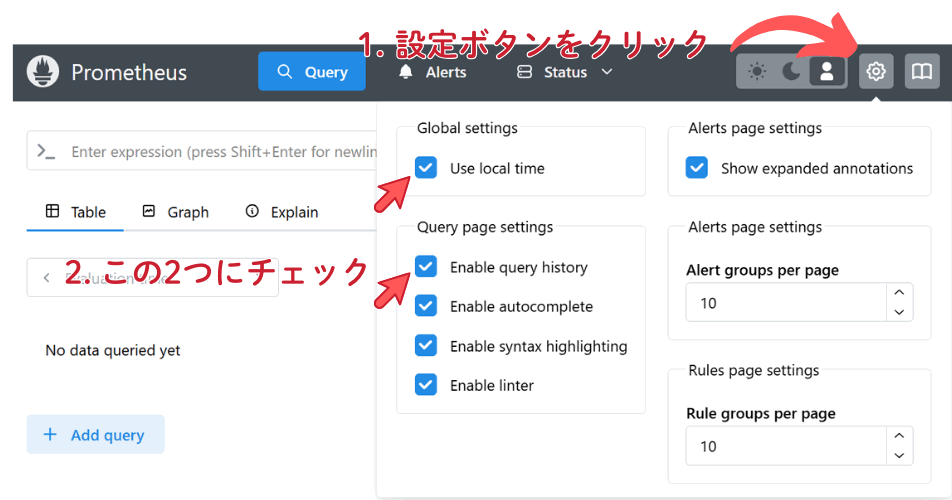
Web UIにアクセス後、次の画像のように2つのオプションを有効にしておくことをオススメする。Prometheusでは時刻をすべてUTC(協定世界時)で扱うことから、日本標準時に変換するには頭の中で9時間加算しなければならない。そこでUse local timeオプションを使うことで、日本標準時に自動変換される。
Web UIでできることを簡単に紹介していく。
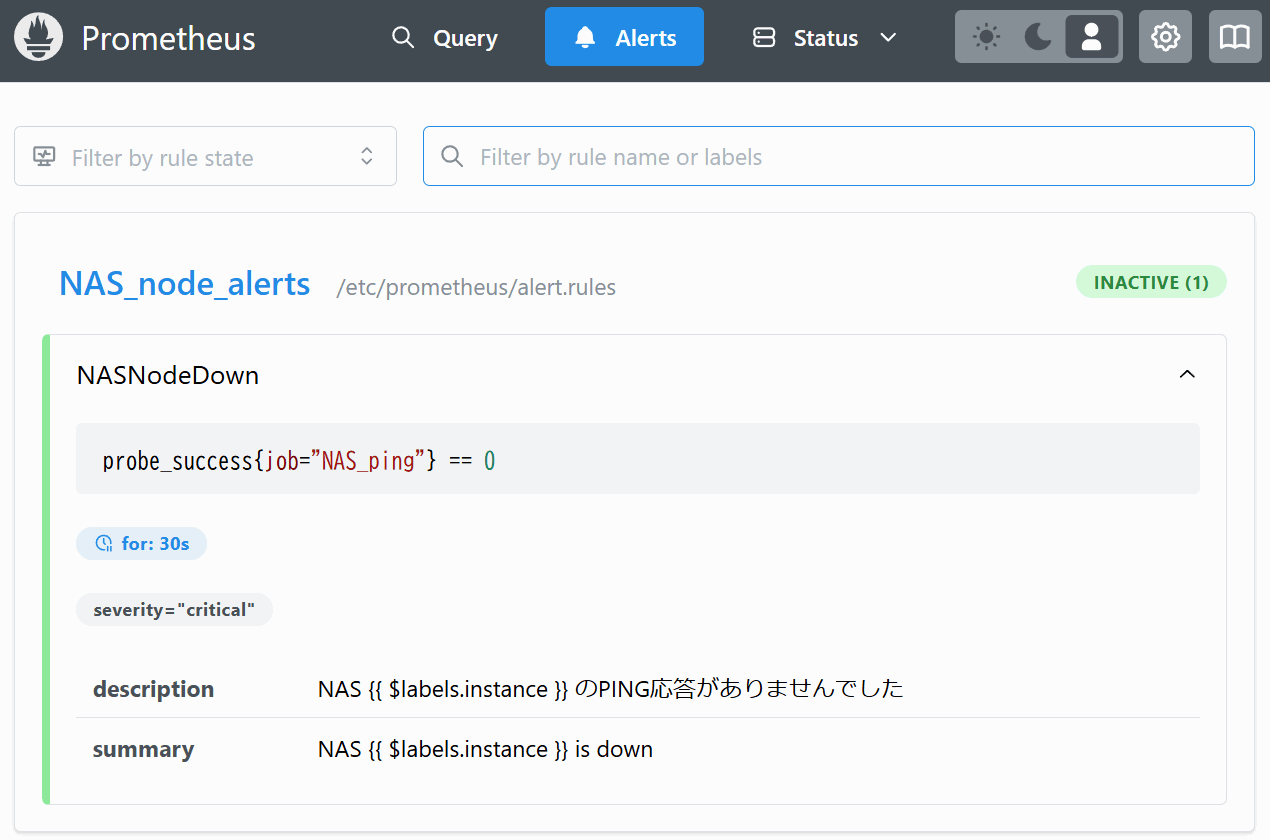
Alerts ページではprometheus/alert.rulesに記載した各アラートの発報状況を確認できる。INACTIVEであればアラートは出ていない状態を示す。
Status > Target healthページではprometheus.yamlで指定したスクレイプ(情報取得)の実施状況を確認できる。Last scrapeでは何秒前にPINGを行ったか、そのときの応答時間を把握できる。
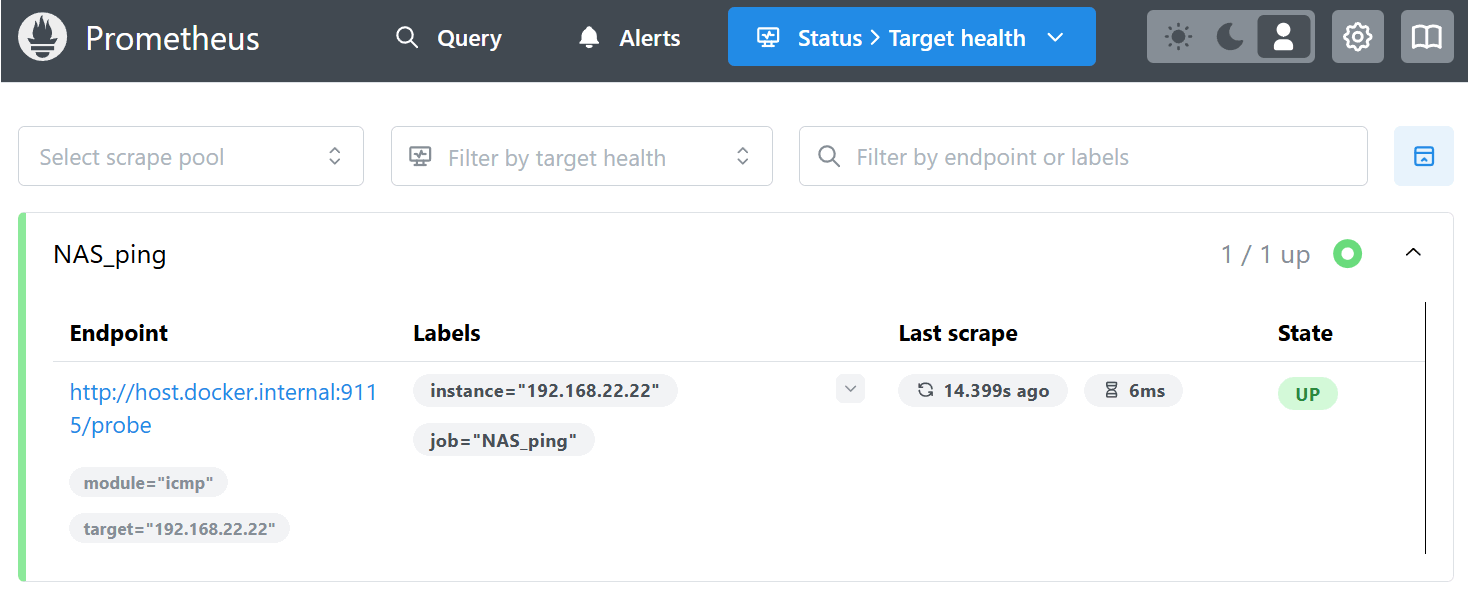
なお後述するが、監視対象へのPingが無応答となっても、この画面のState表示はUPから変化することはないので要注意。結構なハマりポイントである。監視対象のオンライン状態は次のクエリ画面で確認しよう。
メインとなるクエリ画面を操作していこう。PrometheusではPromQL(Prometheus Query Language) という言語を使ってデータ取得や確認を行う点が特徴的だ。
では、Query画面を開いて上部のコマンド入力部>_ へprobe_successとクエリ文を入力し、Executeを押そう。その後、Graphタブを開くと次のグラフ画面が表示される。
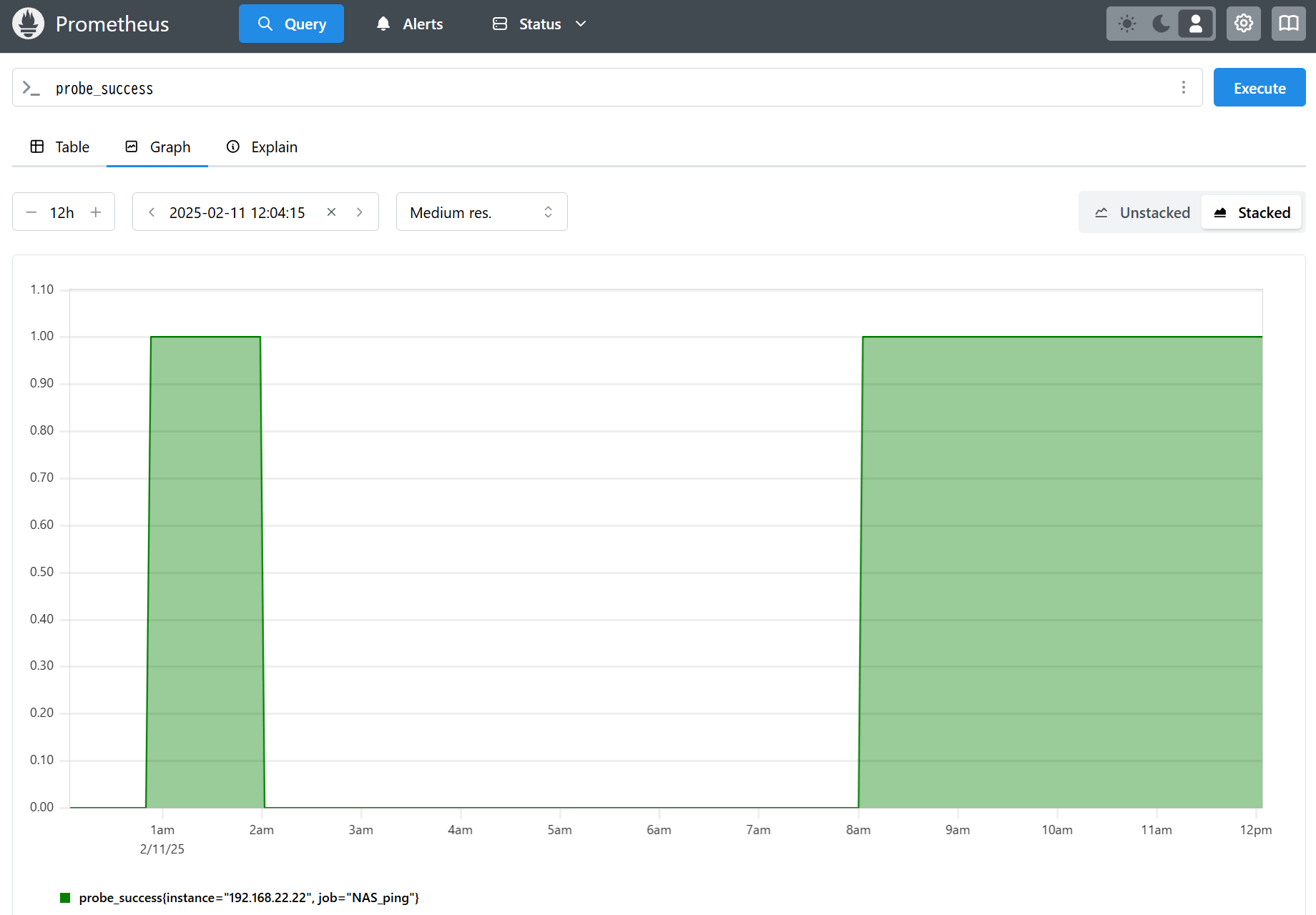
グラフの縦軸が「1」になっている部分がPING応答があった時間帯、「0」の部分がPING無応答となった時間帯を指す。上の画像の例では2am~8amまでPING無応答、つまり監視対象の端末が停止していたことがわかる。
なおprometheus.yamlで監視対象が複数ある場合は以下のようなクエリ文を用いて、probe_successの抽出条件を指定するのがよい。
probe_success{instance="192.168.22.22",job="NAS_ping"}なお、本格的なダッシュボードは Grafana を使用するのが一般的だが、今回の目的は外部へのアラートなのでGrafanaでの可視化は省略する。
やっとここで本題。監視対象の端末を停止させ、Discordへのアラート発報を確認しよう。
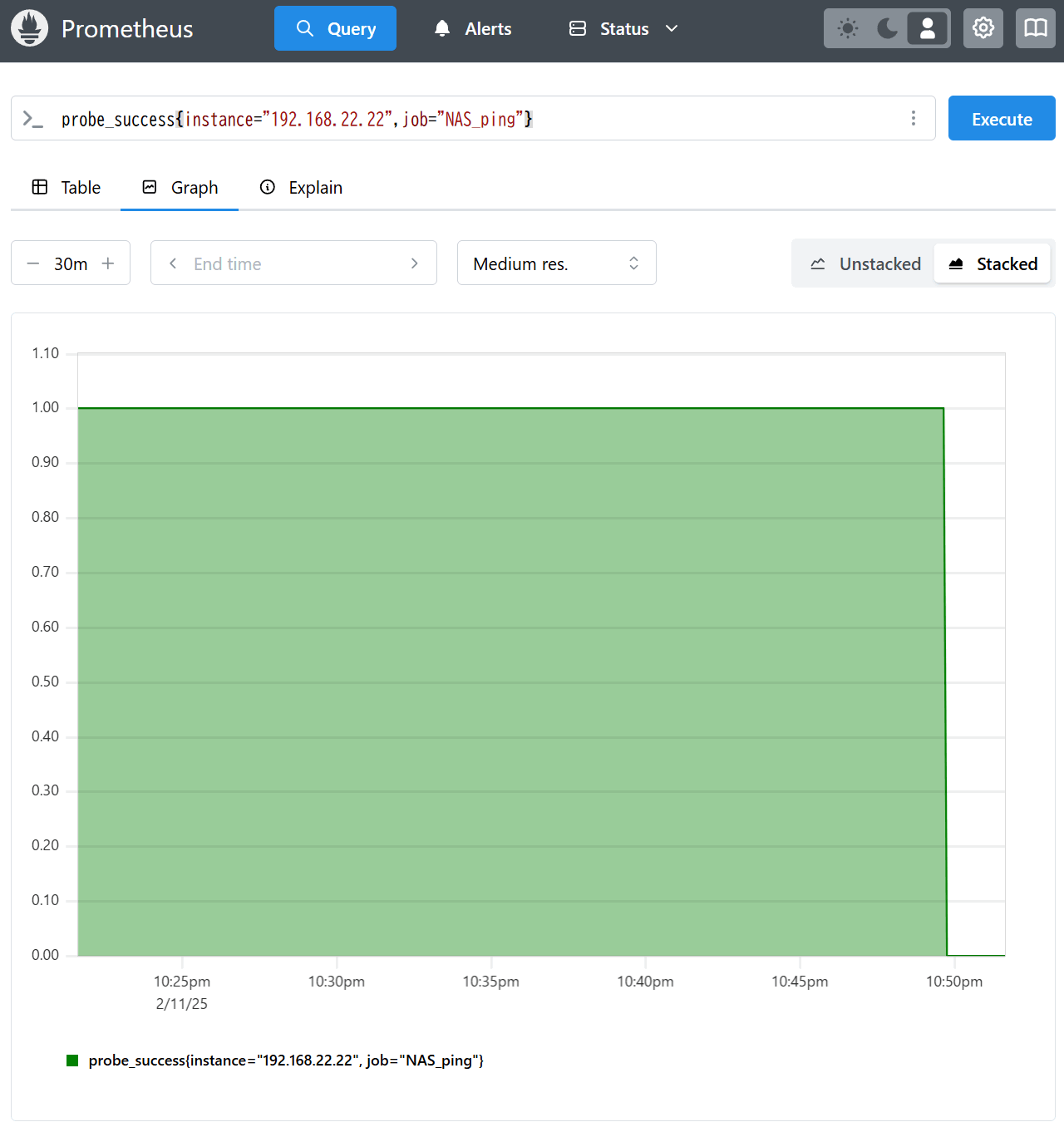
まずはクエリ画面。監視対象のNASをシャットダウンさせたところ、probe_successのクエリ結果が10:49pmに「1:PING応答あり」から「0:PING無応答」へ変化したことがわかる。
次にアラート画面に移る。この画面ではNASNodeDownがINACTIVEからFIRINGへ変化しており、アラートが発報されたことがわかる。
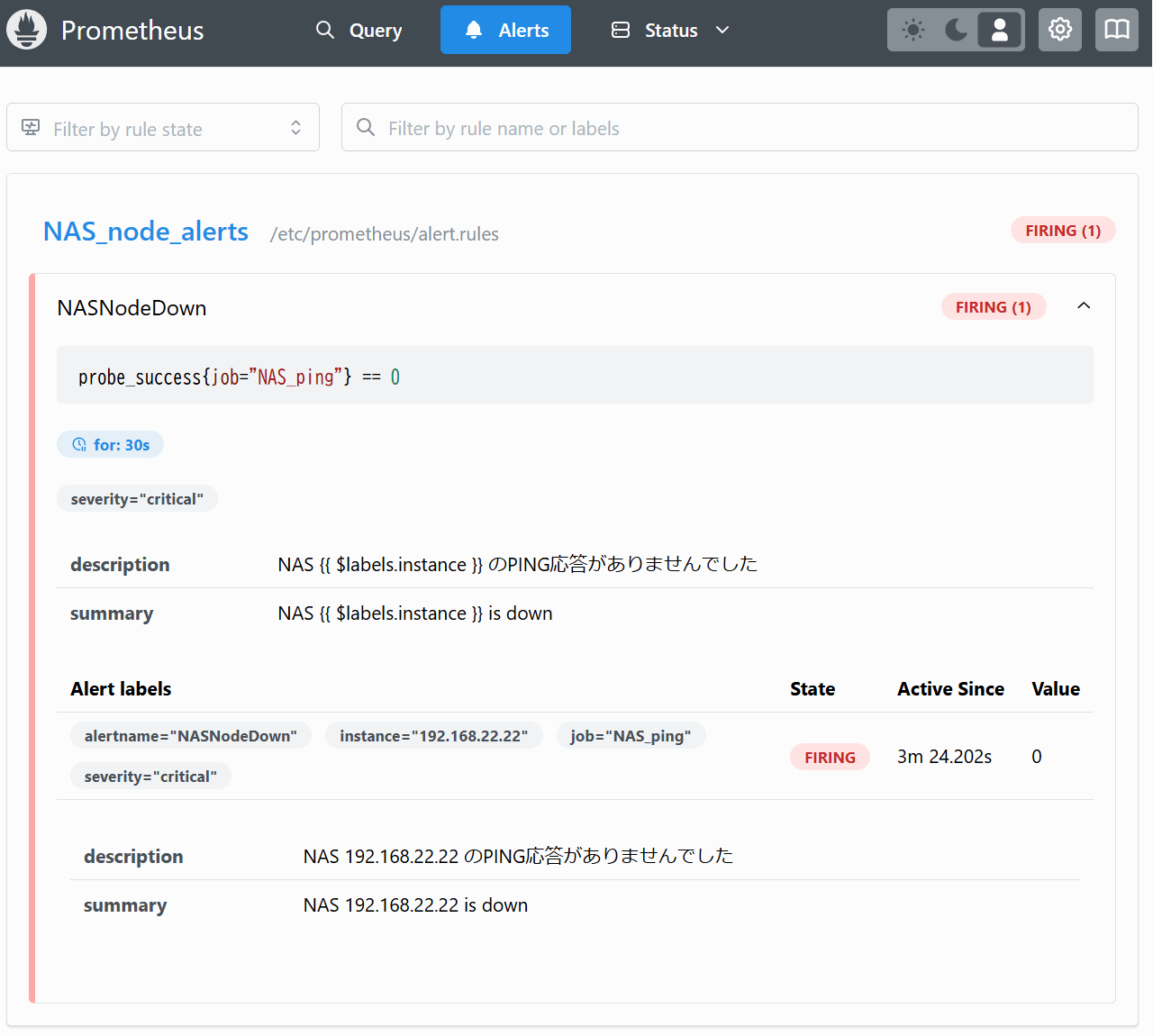
なお、Status -> Target health画面ではStateがUPを示したままになっている。
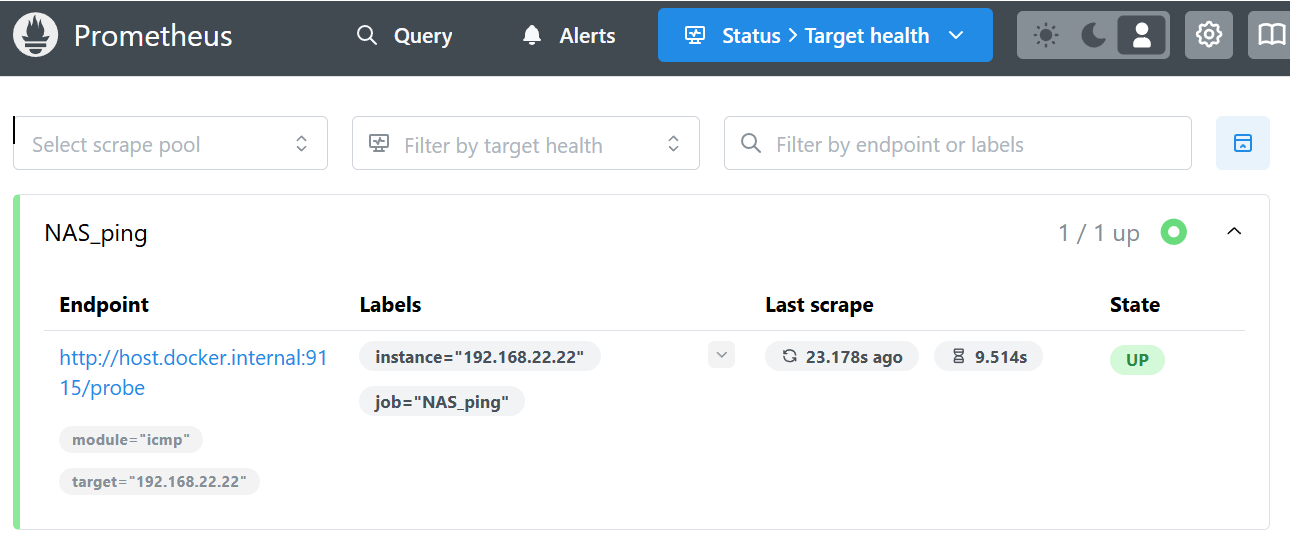
これはPING監視に使用しているBlackbox exporterの仕様のようで「スクレイプ操作は正しく行えているのでUPを示す」考え方のようだ。以下のGithubで議論されている。
そしてDiscordへのアラート発報。無事アラートメッセージが届いているだろうか?
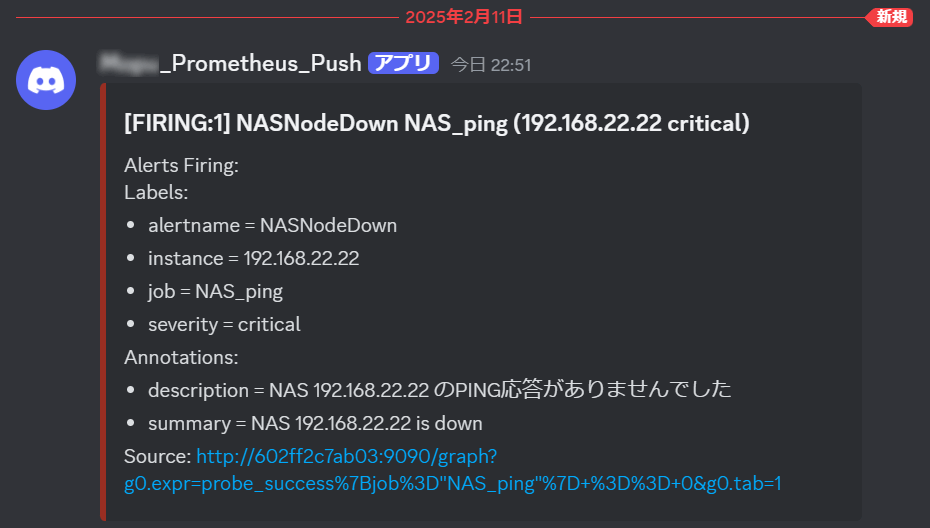
監視対象の端末を起動して、再びPINGが成功するようになると復帰通知がDiscordへ届く。ここまで確認できれば一連の流れは完了だ。
監視対象としているNASは、毎日午前2~8時は自動的にシャットダウンさせている。当然この間、PING無応答となってしまうのでDiscordへアラートが飛ぶのだが、これではオオカミ少年になってしまうのでこの時間帯のみ監視対象外としたい。
そんな悩みもPrometheusならお手のものである。アラートを出したくない(ミュートしたい)時間帯をAlertmanagerの設定ファイルに記入すればよい。
▼ハイライトした行がミュート設定のため追記した箇所
route:
receiver: default-receiver
group_by: ['alertname' , 'job']
group_wait: 30s
group_interval: 5m
repeat_interval: 1d
routes:
- receiver: discord
match:
severity: critical
mute_time_intervals:
- out-of-NAS-Shutdown-hours
receivers:
- name: default-receiver
- name: discord
discord_configs:
- webhook_url: https://discord.com/api/webhooks/****** # DiscordのWebhookURL
mute_time_intervals:
- name: out-of-NAS-Shutdown-hours
time_intervals:
- times:
- start_time: 16:45 # ミュート開始時刻(UTCで)
end_time: 23:15 # ミュート終了時刻(UTCで)このミュート開始時刻と終了時刻はUTC(協定世界時)で指定する必要があるのでJSTから逆算しよう。
今回はPrometheusとBlackbox Exporter、そしてAlertmanagerを組み合わせたPING監視とアラートの仕組みを構築した。
PrometheusはExporterの監視モジュールが用途ごとに分けられているので、必要な機能だけを選んでシステムをシンプルに構築できる点が最高にイケているし、理解しやすい要因だと感じた。
PING監視で物足りなくなったら次はNode ExporterとGrafanaを組み合わせてシステム監視をしてみるのも面白いだろう。
端末やシステムを監視することで、トラブルが起こったときにすぐに復旧に当たれるし、ログを分析して原因を特定することがとても容易になる。ぜひ、自宅にNASやサーバーがある人は監視システムにレッツチャレンジ。
